# Install
$ pip3 install autoscraper
一分钟上手
from autoscraper import AutoScraper
url = 'https://stackoverflow.com/questions/2081586/web-scraping-with-python'
# We can add one or multiple candidates here.
# You can also put urls here to retrieve urls.
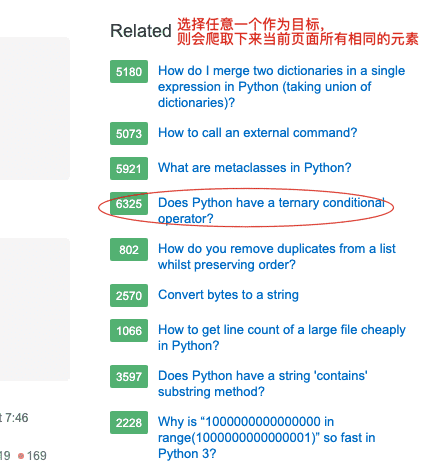
wanted_list = ["How to call an external command?"]
scraper = AutoScraper()
result = scraper.build(url, wanted_list)
print(result)
- url 是你需要爬取的网页
- wanted_list 是一个 list,其中有你需要的元素目标,注意会爬取相同 tag 和范围的数据
更多使用技巧
请关注 Github 仓库: https://github.com/alirezamika/autoscraper